
What is Data Science?¶
Neil Lawrence (2017)
We define the field of data science to be the challenge of making sense of the large volumes of data that have now become available through the increase in sensors and the large interconnection of the internet. Phenomena variously known as 'big data' or 'the internet of things'.
What is Data Science?¶
Data science differs from traditional statistics in that this data is not necessarily collected with a purpose or experiment in mind. It is collected by happenstance, and we try and extract value from it later.
What is Machine Learning?¶
What is Data Science?¶

Why do we do data science?¶
- New features
- Optimising features
- Dashboard for decision making
- Ad-hoc analysis
End to end Data Science¶
It means rethinking traditional data science workflows and embracing new principles that deeply involve the people and communities being studied.
End to end Data Science practices¶
This includes best practices like:
- Involving community members in the selection of study questions
- Partnering with communities in the data generation and curation process
- Being intentional when formulating models, assumptions — can we think like engineers rather than scientists?
- Rigorous, controlled experimentation
- Transparent communication of results back to the community and stakeholders (e.g. policy makers)
Data Science vs AI¶
- The challenge in artificial intelligence is to recreate “intelligent” behaviour.
- Data is acquired from humans, and the computer is given the task of reconstructing that data.
- Role of machine learning techniques is on emulating the data creation process by combining a model with the data.
- The model incorporates assumptions about the data generating process.
Data Science vs Machine Learning¶
- Takes the approach of observing a system in practice and emulating its behavior with mathematics.
- One of the design aspects in designing machine learning solutions is where to put the mathematical function.
- Obtaining complex behavior in the resulting system can require some imagination in the design process.
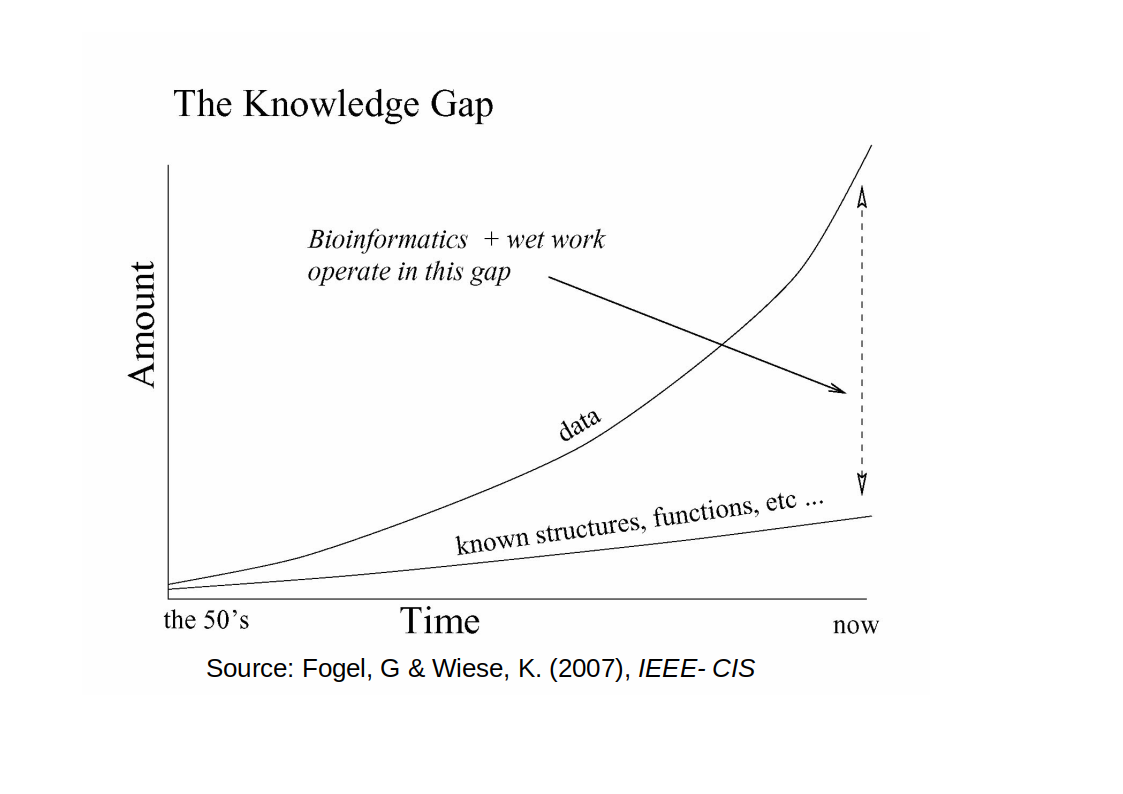
There is a lot of data!¶
Data Science Information Flow¶
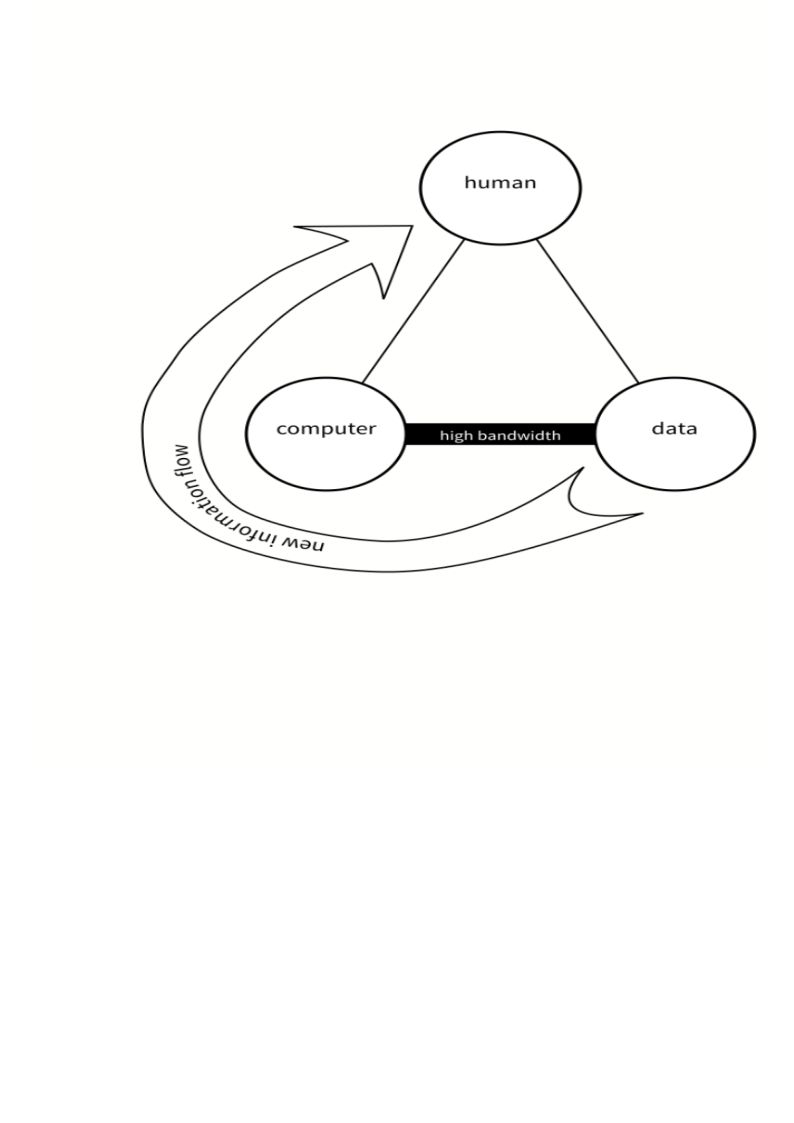
- Large amounts of data and high interconnection bandwidth
- Much of our information about the world around us received through computers
DATA SAVES LIVES¶
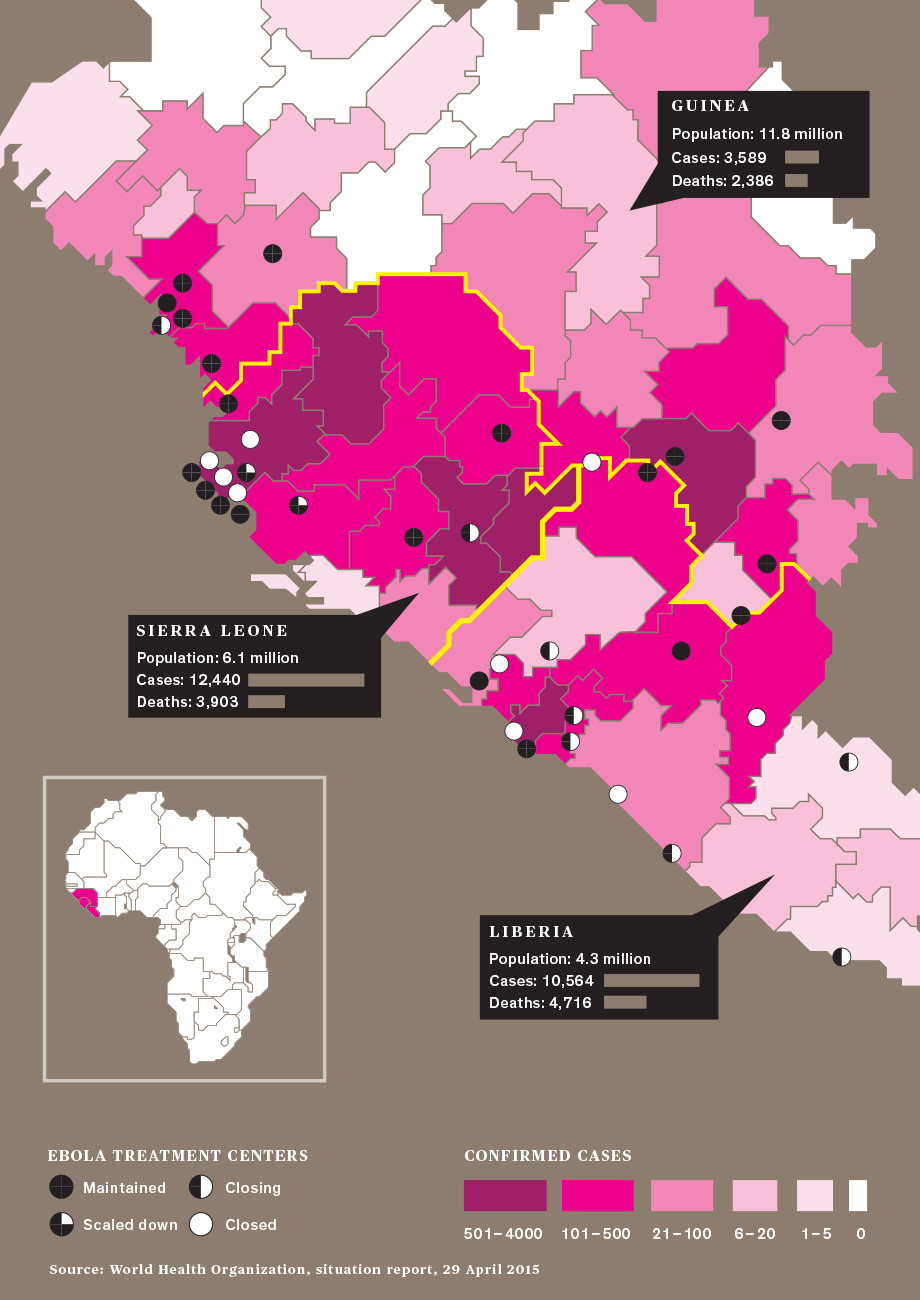
Computer Modelers vs Ebola¶
Goal: Predict the course of the West African Ebola outbreak¶
- The project sought to represent, through mathematical equations, the evolution of a deadly epidemic.
- Ideally, models should be able to predict: how quickly a disease will spread; who is most at risk and where the hot spots will be
- Findings enable public health authorities to take steps that diminish or shorten the epidemic.
To determine optimal locations for six Ebola treatment centers in Liberia¶
- To minimize the distance an infected person anywhere in the six-county area would have to travel for treatment.
- Dataset: population, household size, daily activities, travel patterns, the condition and the existence of roads
- Challenge on the dataset: missing, old, or unreliable
- the distribution of the six counties' populations estimates from LandScan and WorldPop
'Go big, go quick' response¶
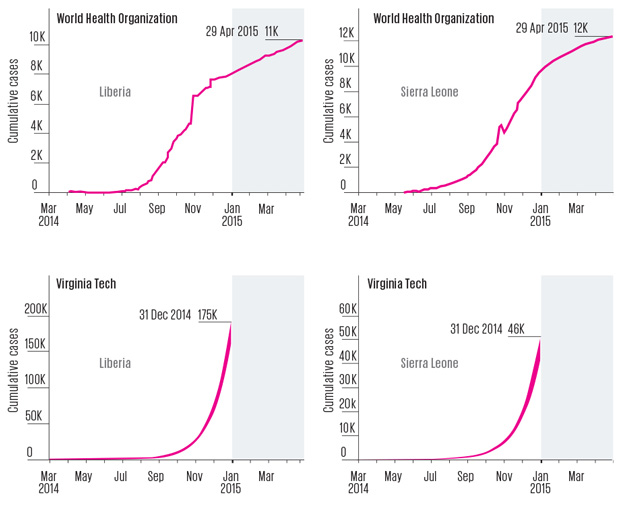
Learning from Lofa¶
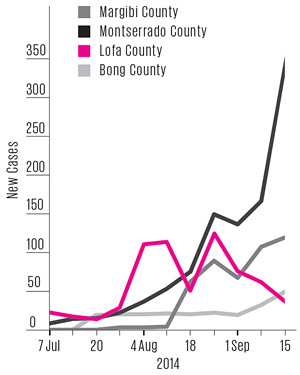
- Many Liberian counties reported alarming numbers of new cases in late August and September 2014
- But in Lofa county, the numbers were dropping.
- Almost nobody noticed.
Worst-case Scenarios¶
- Even inaccurate forecasts helped to quantify interventions:
- singly or in combination
- immediate or delayed
- could change an epidemic's trajectory
- They helped decision makers establish priorities
- They helped to inspire and inform the strong international response that may at last be slowing the epidemic
Data Science is a process¶
- Formulating a quantitative question that can be answered with data,
- Collecting and cleaning the data,
- Analyzing the data and
- Communicating the answer to the question to a relevant audience.
In a nutshell:
- Explore: identify patterns
- Predict: make informed guesses
- Infer: quantify what you know
Skills of Data Scientists¶
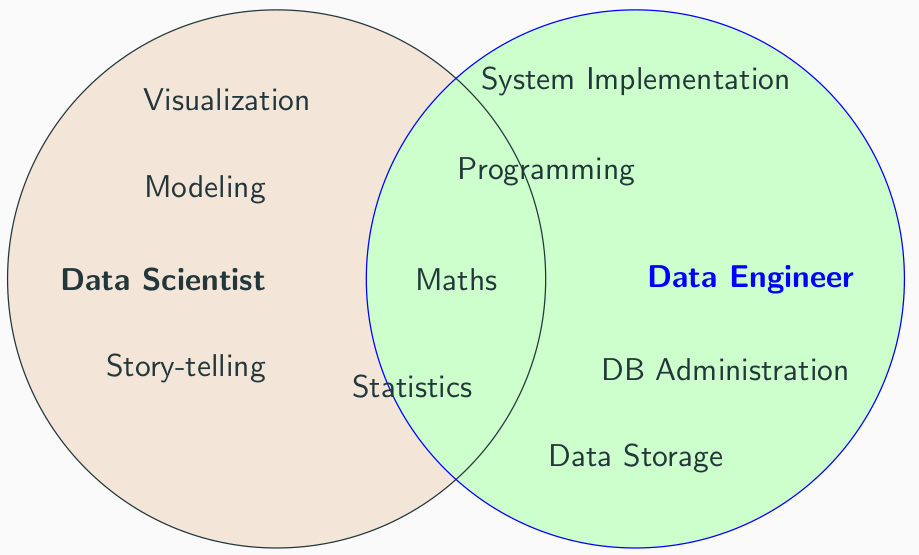
Statistics¶
Statistics refers to the mathematics and techniques with which we understand data. It is a discpline of analyzing data. Statistics intersects heavily with data science, machine learning and of course traditional statistical analysis.
Statistics¶
Key activities that define the field:
- Descriptive statistics (EDA, quantification, summarization, clustering)
- Inference (estimation, sampling, variability, defining populations)
- Prediction (machine learning)
- Experimental Design (the process of designing experiments)
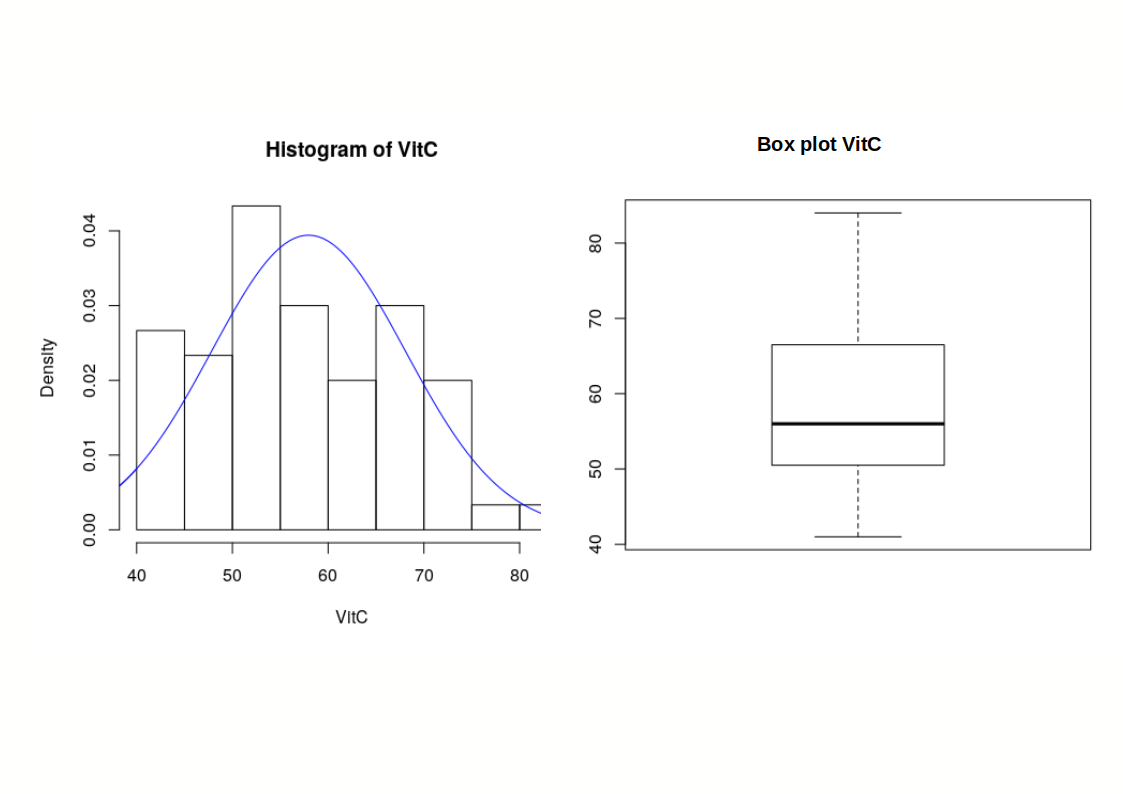
A cabbage field trial - Head Weight¶
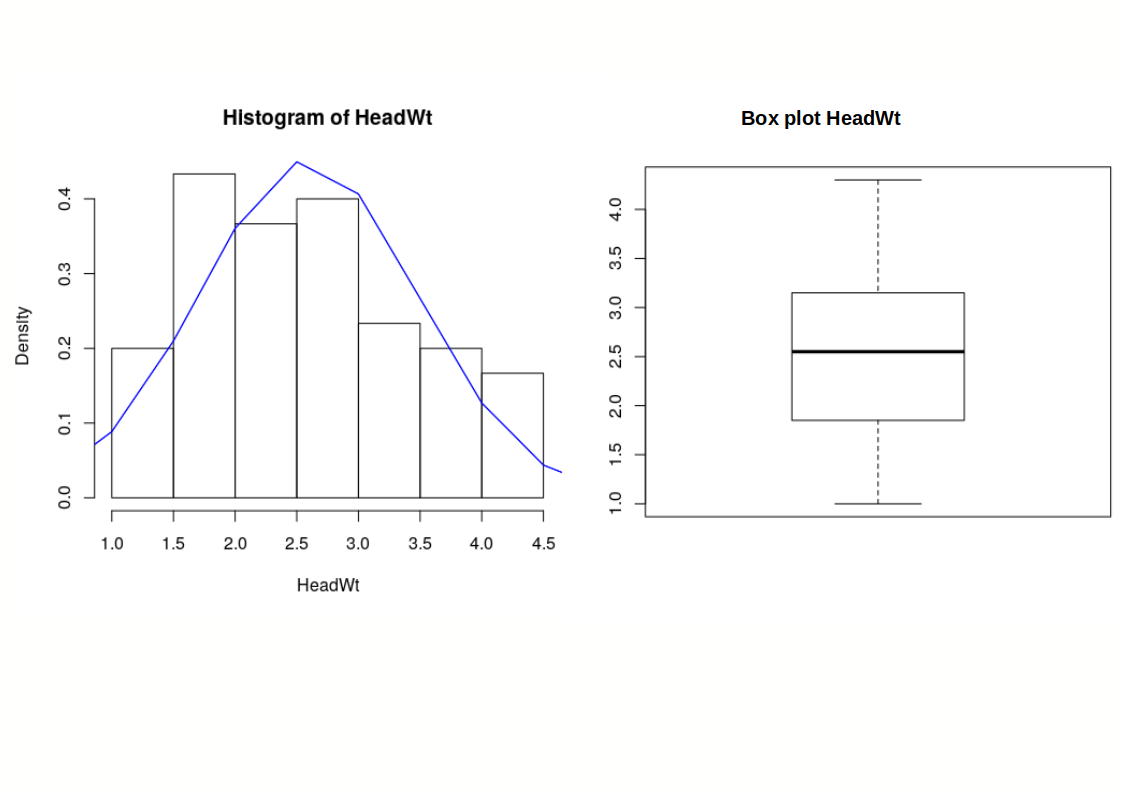
A cabbage field trial - Vitamin C content¶
What is Machine Learning?¶
- The principle technology underpinning the recent advances in Artificial Intelligence.
- The principal technology behind two emerging domains: Data Science and Artificial Intelligence.
- The rise of machine learning is coming about through the availability of data and computation,
- But machine learning methodologies are fundamentally dependent on models.
What is Machine Learning?¶
$$ data + model \xrightarrow{\text{compute}} prediction $$
- data: observations, could be actively or passively acquired (meta-data).
- model: assumptions, based on previous experience (other data! transfer learning etc).
- prediction: an action to be taken or a categorization or a quality score.
Machine Learning Approaches¶
1. Supervised Learning¶
- Learn a model from a given set of input-output pairs, in order to predict the output of new inputs.
- Further grouped into Regression and classification problems.
2. Unsupervised Learning¶
- Discover patterns and learn the structure of unlabelled data.
- Example Distribution modeling and Clustering.
3. Reinforcement Learning¶
- Learn what actions to take in a given situation, based on rewards and penalties
- Example consider teaching a dog a new trick: you cannot tell it what to do, but you can reward/punish it.
Machine Learning vs Traditional Statistical Analyses¶
| Machine learning | Traditional statistical analyses |
|---|---|
| Emphasize predictions | Emphasizes superpopulation inference |
| Evaluates results via prediction performance | Focuses on a-priori hypotheses |
| Concern for overfitting but not model complexity per se | Simpler models preferred over complex ones (parsimony) |
| Emphasis on performance | Emphasis on parameter interpretability |
| Generalizability is obtained through performance on novel datasets | Statistical modeling or sampling assumptions |
| Concern over performance and robustness | Concern over assumptions and robustness |
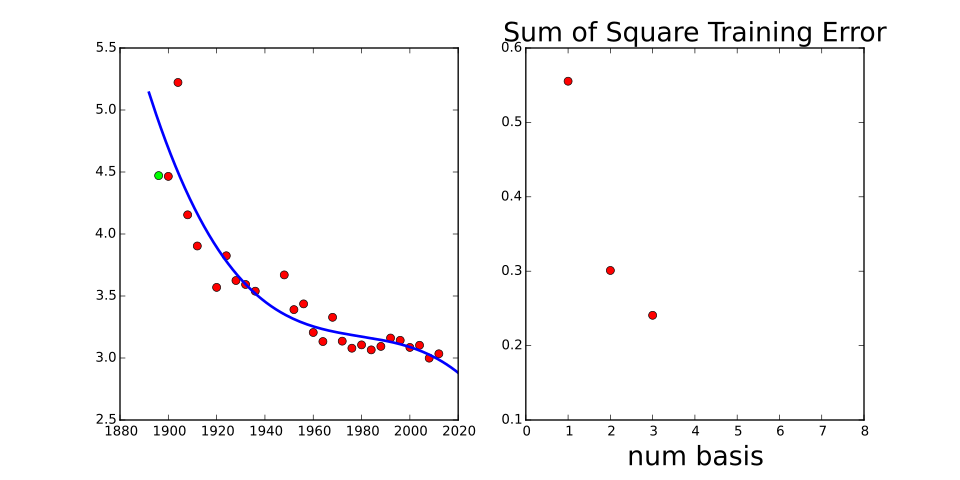
Example of Prediction¶
- The Olympic gold medalist in the marathons pace is predicted using a regression fit.
- In this case the mathematical function is directly predicting the pace of the winner as a function of the year of the Olympics.
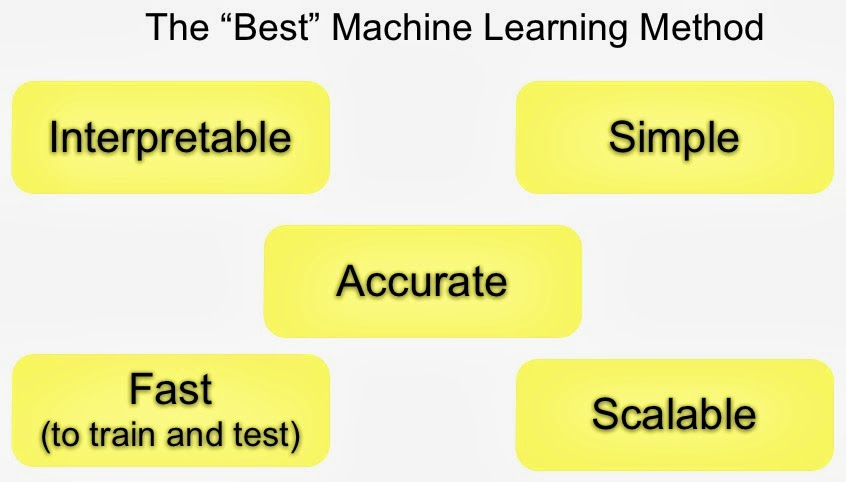
Trade-offs on Machine Learning¶
Data Science Pipeline (end to end)¶
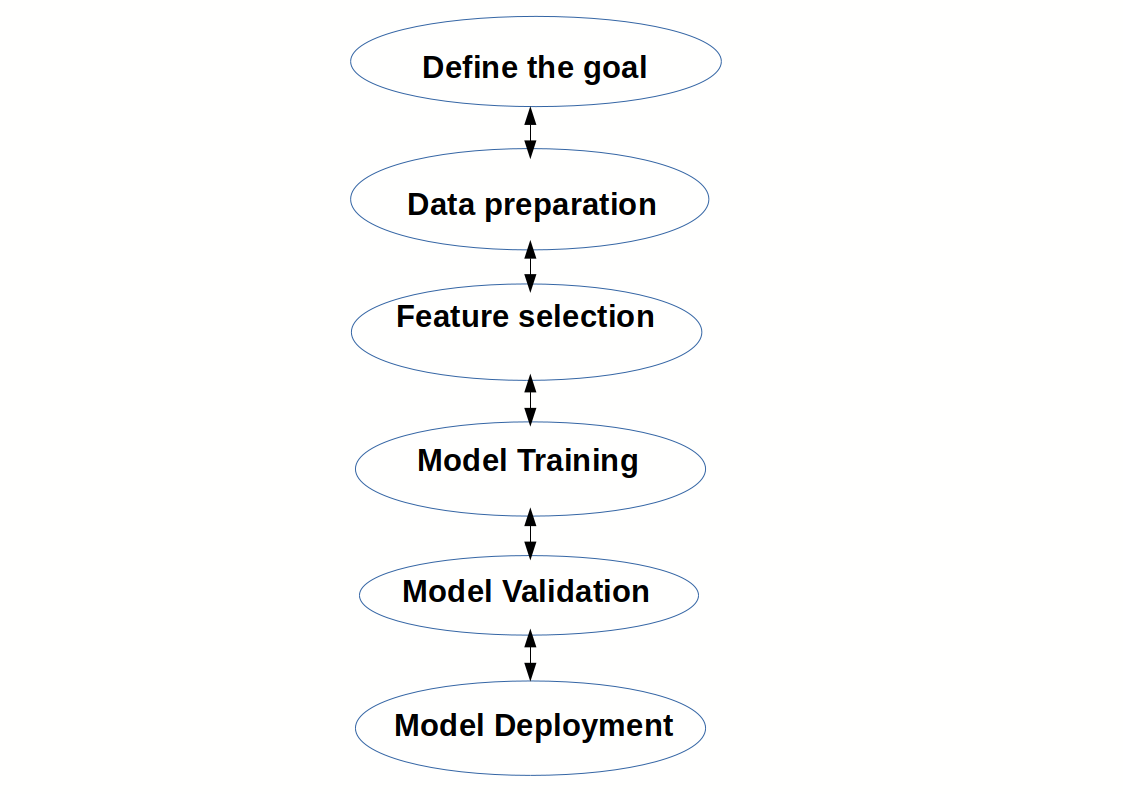
End-to-end predictive analytics approach¶
STEP 1: Define the goal
STEP 2: Data understanding and preparation
- Importing, cleaning, manipulating and
- Visualizing your data
STEP 3: Building your machine learning model
- Feature selection
- Model training
- Model validation
STEP 4: Model deployment
Data Science Products Requisites¶
- Robust: the testing error has to be consistent with the training error, or the performance is stable after adding some noise to the dataset.
- Reproducible: the only way to confirm scientific findings are accurate and not the artifact of a single experiment or analysis
Recommendations to achieve Robustness¶
- Good experimental design
- Write code as cleverly as possible: simple, clear code makes debugging easier.
- Automate tasks, it decreases trivial mistakes by humans.
- Make assertions in code and in your methods
- Test code
- Use existing libraries whenever possible
- Let data prove that it's high quality, e.g. using EDA
- Treat data as Read-Only
- Develop frequently used scripts into tools
Recommendations for Reproducible Projects¶
- Release your code and data
- Document everything
- Make figures and statistics the results of scripts
- Use code as documentation
Best Practices¶
- Solve the right problem
- Fail better everyday
- Data quality matters
- Simplicity is your friend
- Debugging makes you a wizard
- Fairness and privacy are not dirty words
References¶
C. M. Bishop. Pattern Recognition and Machine Learning. Springer-Verlag, 2006.
Neil Lawrence (2017), What is Machine Learning?
Vince Buffalo, Bioinformatics Data Skills, O'Reilly Media, Inc., 2015.