Introduction
In the era of big data, datasets are what power large machine learning models in many settings. From agriculture to credit lending and healthcare interventions, data is needed to train models, make predictions, and thus inform decisions in society. However, in many countries, data is often scarce and the task of data collection can be daunting without the infrastructure in place to facilitate it. Together with researchers in Tanzania, Uganda, and the U.S. and agriculture experts and small-scale farmers, our team was able to embark on this arduous task and collect a total of 6,812 poultry fecal images across four classes of healthy, Coccidiosis, Newcastle and Salmonella poultry diseases in Tanzania. In this article, we will discuss our process for such a collection, the tools we used, and the lessons we learned. While our data collection process includes tools and methodology for the specific purpose of collecting poultry images to classify healthy and diseased poultry, we hope that documenting our process can help inform other data collection tasks in resource-constrained settings and inspire future work in this area.
What you’ll need
Data collection is an underestimated, expensive and time-consuming task. Poultry farmers in Tanzania operate on a small scale and many times don’t have a systematic way to collect, analyze and store information about their farms. As a result, many of them do not immediately see the value of data in running their enterprises nor are they aware of the potential harms.
It is necessary and must be done correctly in order to proceed to the next step of building a machine learning model. Getting your data in order is arguably the most important and most difficult task compared to modeling in the machine learning pipeline. One must be organized and have clear systems in place before the data collection can begin. We asked farmers to sign consent and privacy forms to ensure that their information would be protected. We also applied for ethical clearance from Government authorities to conduct the project. We then used the Open Data Kit (ODK) to collect all the images using smartphones and stored all of the images on Google drive. ODK is a standard tool for mobile data collection with support for geo-locations, images, audio clips, video clips, barcodes, numerical and textual answers.
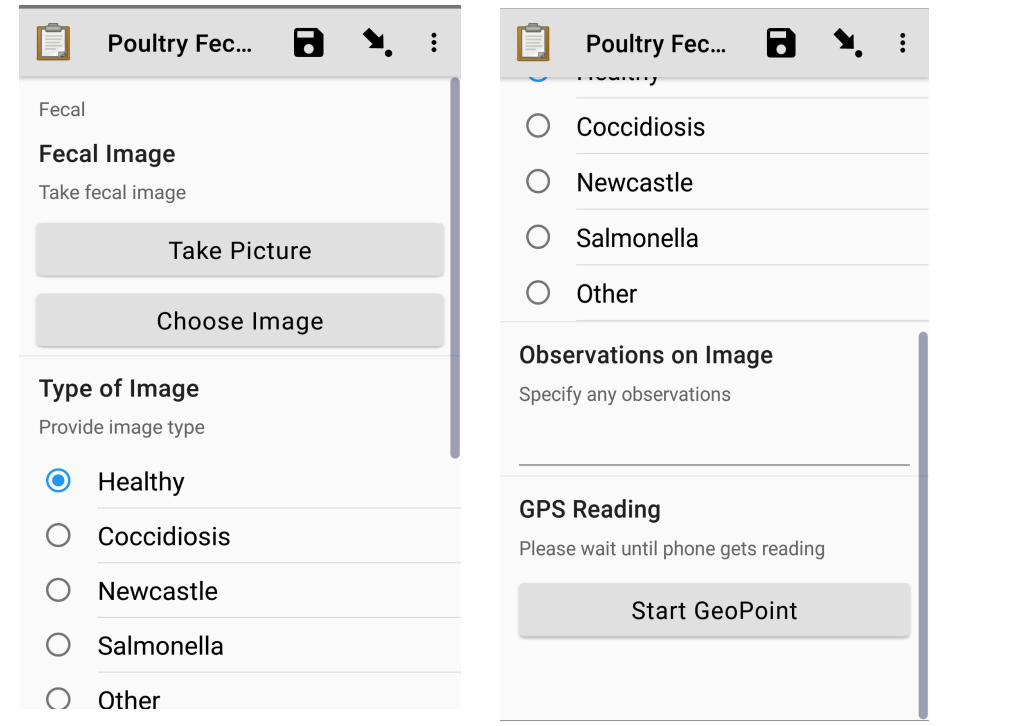
Figure 1: ODK form for collecting fecal images at the study sites and the sample responses uploaded in Google drive
A Typical Day
Let us first walk through a typical day in our data collection procedure. First, we scheduled appointments with each farm a few days in advance. This was primarily done by the field officers on our team. We describe their role in detail in future sections of this blog. The day before we would send reminders to farmers as well as ask farmers to sign a consent form that gives us permission to take images of their farms. Before embarking on the journey to each farm, we also needed to double-check that all the tools on ODK were working properly and are properly loaded onto the enumerator’s phone. Then our journey begins bright and early the next morning. Typically, we aimed to arrive at each farm by 9 AM Tanzania time, which varied in distance from 30 minutes away in Arusha to 2 hours away in Kilimanjaro.
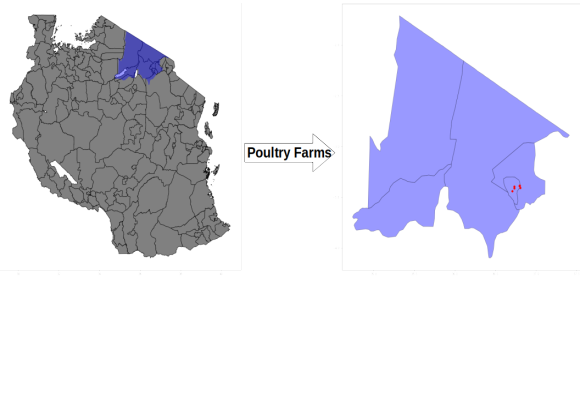
Figure 2: Map of Tanzania. The purple-colored region is Arusha where some of the farms we traveled to are located.
There were two main actors that are instrumental to the accurate and timely collection of this data: the veterinarian and the field officer. The veterinarian is the expert on poultry diseases, and not only would they help us collect the diseased and healthy classes but they would also later provide advice and free services to the farmers we visited. The field officer provides up-to-date information on government regulations and policies around land use and agriculture. The field officer has much of the same knowledge as the veterinarian but without the training. They have a thorough understanding of the farms in their locale. There are also far more field officers than there are veterinarians. Together with our interns, the veterinarian and the field officer would be escorted around the farm by the farmer. The interns would begin taking photos and immediately upload the images to our server using the mobile application we developed. It takes approximately 1 - 2 minutes to upload a photo to the server and enumerators typically take 150 - 200 photos each per farm per day. Additionally, we usually have two teams visit two different farms per day. The team also needs to take extra precautions to prevent any undue harm to the chickens. Before leaving each farm, the team must notify the researchers once their photos have been uploaded to Google Drive. This gives researchers a chance to ensure that the images are stored correctly and that the proper information was collected. With time, the team on the ground gets faster and is less prone to error.

Figure 3: [Left Image]The on-the-ground team consisting of the veterinarian (left), the field officer (right and middle in lab coat), and the intern (in the middle). [Right Image] The enumerators (field officer on left and intern holding tablet) are using the mobile application to capture the fecal image and upload it to Google drive.
This project has been three years in the making. It took time to build trust with farmers and train veterinarians and field officers to use our mobile application, as well as get buy-in from everyone on the benefits of the tools we are hoping to build. Now farmers want to know when they are going to have the tools ready in their hands to use. While our team is working diligently to develop that for them, this is only the beginning. We hope to have training for the farmers on how to use the crowdsourcing application themselves and focus groups on how we can make the application better. We want to involve farmers as much as we can in the design and creation of these tools.
Next steps
Once we have all of the images collected, we now need to prepare the images for computer vision tasks such as image segmentation, image object detection, and image classification. We begin by first renaming the images in each class to be the class name and a number (i.e. “cocci1.png” or “health56.png”). We then store the mapping of the original file name and new file name in a data frame along with other metadata about the image. We also store each image in a folder labeled by train, validation, and test sets, then within those three folders are another set of folders labeled by each class. We also rescale the images accordingly for each class and store a copy of the images for each computer vision task in its own folder. The data is now ready to be accessed either through Google collab python notebooks or on your own local repository to train models on.
Ethics in Agriculture
As machine learning researchers, much of our work relies on the proper collection of data. We make model assumptions and conclusions based on how the data is collected but often times we are not involved or unaware of the data collection process. For this project, we believe that it is part of our job as researchers to be on the field and directly involved in collecting the data in order to ensure an ethical collection and to build trust with our stakeholders. In the context of agriculture, our primary ethical concerns are privacy, representation, and equity. We take steps to ensure that the privacy of farmers is kept secure. We do not collect any identifying information, that isn’t already public record or information related to the yield and profitability of farms. We also asked farmers to sign a consent form and have interns and staff on-site to answer any questions that farmers may have. Also, we continue to collect crowdsourced data, we will need to take steps to ensure an equal representation within the training data to ensure fair predictions. For example, we may want to ensure that predictions on farms in Arusha have similar accuracy to predictions on farms in Kilimanjaro. We also want to ensure equitable outcomes for farmers. We do not want the benefits of this project to be one-sided or only benefit subgroups. We need to discuss with farmers and domain experts ways in which we can ensure that each of these concerns is addressed.
In recent literature on AI ethics, researchers are often concerned with historical biases that exist in the data but are unaware of how the data was collected. Data collection raises questions of power and benefits to the communities that they work in. Questions such as “What benefits do those included in the dataset receive? Do individuals in the dataset reap the same benefits as the data curators? What are the potential harms that this data could cause to the communities they represent? [1]” Additionally, one could also ask questions of diversity and fairness such as “Does the data represent a diverse and accurate target population? How do dataset properties affect the learning procedure?” We tackle some of these questions by developing a “Datasheet” for our dataset [2]. We encourage all researchers to take this step as a part of their data collection procedure.
Conclusion
Data collection is essential to many of the machine learning systems that exist today. Oftentimes, the more data one has the more accurate model predictions can be. In a resource-constrained setting, the process of data collection can have a lot of implications for the models that researchers chose to build and problems that researchers chose to take on. Additionally, there are ethical challenges that come with data collection. We hope that we have illuminated some of the pressing issues that we faced as well as steps that we took to overcome them. We also would like to emphasize the growing literature on collecting data ethically and equitably [3] as we believe that our work and many of the AI research being done in the Global South are uniquely positioned to push this research forward.
References
-
Rediet Abebe, Kehinde Aruleba, Abeba Birhane, Sara Kingsley, George Obaido, Sekou L. Remy, and Swathi Sadagopan. 2021. Narratives and Counternarratives on Data Sharing in Africa. In Conference on Fairness, Accountability, and Transparency (FAccT ’21), March 3–10, 2021, Virtual Event, Canada. ACM, New York, NY, USA, 12 pages. https://doi.org/10.1145/3442188.3445897
-
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daume III, Kate Crawford. Datasheets for Datasets. 2020. arXiv preprint.
-
Esther Rolf, Theodora Worledge, Benjamin Recht, and Michael I. Jordan. Representation Matters: Assessing the Importance of Subgroup Allocations in Training Data. 2021. arXiv preprint.